

Andrew @generalising@mastodon.flooey.org
Librarian and occasional researcher. Opinions of course my own. Scholarly communications, historic MPs, Wikipedia, inter alia other things. Misplaced Scot.
Joined Nov 2022
Since I seem to have accidentally reminded a lot of people about 'outwith' this week https://www.scottishpoetrylibrary.org.uk/poem/outwith/
Good news: the results of an intensive international project have let us delay having to implement technically complex "negative leap seconds"...
Bad news: ...that project is humanity melting the icecaps
huh, this is neat! someone did an AI-detector-tool based analysis looking at preprint platforms, and released it on exactly the same day as mine. Shows evidence for differential effects by discipline & country. https://www.biorxiv.org/content/10.1101/2024.03.25.586710v1
Is there more we could look at here? Definitely. Test for different tells - the list here was geared to distinctive words *on peer reviews*, which have a different expected style to papers. Test for frequency of those terms (not just "shows up once"). Figure out where they're coming from (there seems to be subject variance etc).
Glad I've got something out there for now, though.
Is it getting worse? You bet. Difficult to be confident for 2024 papers but I'd wildly guess rates have tripled so far. And it's *March*.
Is this a bad thing? You tell me. If it's a tell for LLM-generated papers, I think we can all agree "yes". If it's just widespread copyediting, a bit more ambiguous. But even if the content is OK, will very widespread chatGPT-ification of papers start stylistically messing up later LLMs built on them? Maybe...
Can we say any one of those papers specifically was written with ChatGPT by looking for those words? No - this is just a high level survey. It's the totals that give it away.
Can we say what fraction of those were "ChatGPT generated" rather than just copyedited/assisted? No - but my suspicions are very much raised.
Isn't this all a very simplistic analysis? Yes - I just wanted to get it out in the world sooner rather than later. Hence a fast preprint.
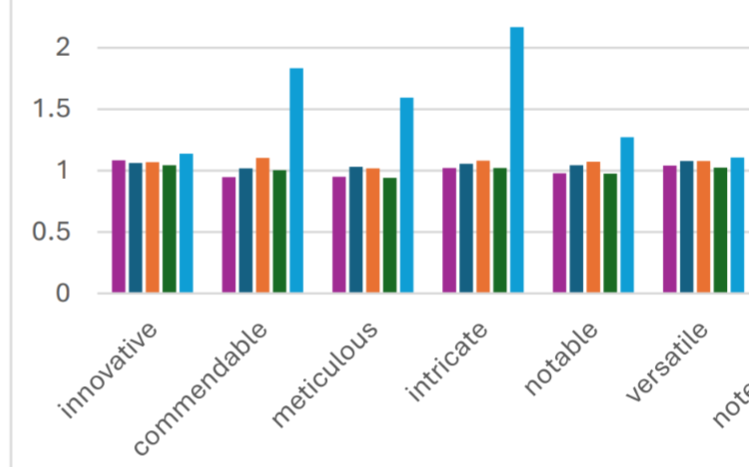
I looked at 24 words that were identified as distinctively LLMish (interestingly, almost all positive) and checked their presence in full text of papers - four showed very strong increases, six medium, and two relatively weak but still noticeable. Looking at the number of these published each year let us estimate the size of the "excess" in 2023. Very simple & straightforward, but striking results.
I have a preprint out estimating how many scholarly papers are written using chatGPT etc? I estimate upwards of 60k articles (>1% of global output) published in 2023. https://arxiv.org/abs/2403.16887
How can we identify this? Simple: there are certain words that LLMs love, and they suddenly start showing up *a lot* last year. Twice as many papers call something "intricate", big rises for "commendable" and "meticulous".
Second favourite bit is the point where our protagonist has to improvise a political speech without knowing precisely a) who he is meant to be or b) whether the meeting was for the Liberals or the Conservatives https://youtu.be/aalwXQINtio
Watched The 39 Steps last night. Absolutely delighted that in 1935, Hitchcock thought through what a modern audience would be waiting for and gave us a character announcing "we've a room, but there's only one bed".
(Same thing in North by Northwest as well. Man knew what clichés he liked.)
Andrew
boosted

i just recieved one of the most unhinged spam emails of my years as a user of email. it sounds like it was written by a person locked in a room with nothing but a thesaurus and a 10-strip of acid. the fact that it ends in the usual fake paypal invoice only makes it funnier.
Andrew
boosted

NEWS:
Due to problems with our site upgrade, we are dropping the paywall, allowing full access to all our material.
https://www.british-history.ac.uk/
Additionally, due to problems with search, we are temporarily making available the old version of our site.
Andrew
boosted

Use a red cross illegally in your video game and then remove it just so you can have a patch note that reads “fixed Geneva Convention violation”
Andrew
boosted

Several of us overly online biologists spent years quietly doing an experiment on Twitter, trying to find out if tweeting about new studies from a set of mid-range journals caused an increase in later citations, compared to set of untweeted control articles.
Turns out we had no noticeable effect; the tweeted papers were cited at the same rate as the control set.
Our paper, headed by Trevor Branch, was published today in PLOS One:
https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0292201
Andrew
boosted

Great story about how YouTube helped with moving away from IE6.
"Our most renegade web developer, an otherwise soft-spoken Croatian guy, insisted on checking in the code under his name, as a badge of personal honor, and the rest of us leveraged our OldTuber status to approve the code review."
I swear that wasn't me. Although I would have loved to do it.
This is a really interesting (if obviously very bleak) piece on state compensation for deaths, and I realised while reading it I have absolutely no idea what to think about a lot of this. https://www.theguardian.com/uk-news/2024/mar/09/london-bridge-terror-attack-why-did-victims-families-get-wildly-different-payouts
Andrew
boosted

What idiot called it "our glorious AI future" instead of "Nightmare on LLM Street"?
Andrew
boosted

{kind=link}
{kind=link}
{kind=link}
"The most important lesson to figure out is why it is taking so long to restore services. That will tell us how to prevent such a calamity in other vital national institutions."
On the matter of the British Library cyber incident https://ciaranmartin.substack.com/p/on-the-matter-of-the-british-library
Enjoyed this: the world of amateur photography in the late USSR. https://kosmofoto.com/2021/03/amateur-photography-in-the-ussr-part-one/ & https://kosmofoto.com/2021/04/amateur-photography-in-the-ussr-part-two/
(I think my favourite detail is that the vast majority of flash units were wall powered...)
"If we can't pay a fair Pension, then how can we afford foreign adventurism, nuclear weapons, armies, royals, pageantry, MP's salaries, etc?"
Total defence budget: £45bn. So that's just £245bn we need to find by slashing, er, MPs salaries and the royals. Feel like we might struggle to balance the books on this one.
Librarian and occasional researcher. Opinions of course my own. Scholarly communications, historic MPs, Wikipedia, inter alia other things. Misplaced Scot.
Joined Nov 2022
